Measuring Move Difficulty in Chess
This article introduces a move difficulty metric developed at Nova Chess that measures how likely a player is to make a costly mistake in a given position. The metric uses multiple simulated agents at different strength levels to produce real-time difficulty assessments that run alongside standard engine analysis. Applications include broadcast enhancement, difficulty-adjusted game analysis, time management assessment, and opening preparation. The metric is already integrated into the Nova Chess analysis interface, where it appears as a difficulty bar alongside the traditional engine evaluation bar (can be activated in the Account page).
- We developed a difficulty metric that correlates strongly with puzzle ratings and with the magnitude of mistakes in actual game positions, across all tested player strength levels.
- Difficulty is measured as expected regret, which quantifies how much win probability a player is likely to lose based on how players of that strength level actually choose moves in similar positions.
- Our multi-agent approach captures how the nature and cost of mistakes vary between stronger and weaker players, ensuring a consistent metric across the rating spectrum.
Note: The results published below are from an early version of the model, which is being refined and improved over time.
You can try the metric using the interactive board below.
Try It: Position Difficulty Analyzer
Or try a sample position:
The Limitations of Engine Evaluation
The development of chess "engines" such as Stockfish has revolutionized chess, whether as a pastime, competitive endeavor, or spectator sport. A strong chess engine can search millions of nodes per second, and in less than a second of processing time can evaluate any position and assess the position quality and best candidate moves as well as a strong Grandmaster could. At higher levels of thinking time ("search depth"), engines will vastly outperform even the strongest of humans. A hobbyist who plays a game on Chess.com can immediately analyze their game afterwards using Stockfish or other chess engines, and see where they made mistakes. Competitive players, particularly chess professionals, use engines not only to analyze their games, but also for deep opening preparation where they explore deviations from opening theory that can take their opponents by surprise. And being able to show an evaluation bar, which indicates how much the current position favors white or black – assuming optimal play – has increased the appeal and engagement of chess broadcasts.
Despite the transformative impact of engine evaluation on the chess experience, the evaluation bar has a fundamental drawback: it tells us nothing about how difficult the position is for the player who must actually make the next move. A position can be evaluated at +0.00 (dead equal, again assuming optimal play) and yet require a counterintuitive move that only the most resourceful of Grandmasters would find over the board. Likewise, a position can show an evaluation of +5.0, indicating an overwhelming advantage for white, and the winning continuation may be a simple recapture that a beginner could play easily find. The engine's assessment of the position and the practical challenge of navigating it are two entirely different dimensions of information, and existing tools generally provide only the former. Chess commentators will often use phrases such as "the better side of equality" to describe positions where the evaluation bar shows a balanced position, but experience informs us that one side has more practical chances to realize and eventually convert an advantage.
This limitation of using only the evaluation bar to assess game outcome probabilities is consequential. A viewer watching a broadcast sees the evaluation bar tilt and knows someone is winning, but has no indication of whether the next move is a routine developing move – where perhaps even many straightforward moves would lead to victory – or a highly difficult decision that will test the player into making a choice that may determine the game outcome. A player reviewing their game can identify where they blundered, but cannot distinguish between a blunder in a position where the correct move was straightforward and one where the correct move was much more difficult to find, which would naturally have different implications for self-assessment and improvement. And while strong coaches can apply their chess understanding to gauge the difficulty of a move or position, there is no objective standard for the concept of difficulty, as there is for raw evaluation. In each case, the missing variable is a measure of how difficult the position is from the perspective of the player sitting at the board.
Defining Difficulty: Expected Regret
The first challenge in building a difficulty metric is establishing a rigorous definition of what "difficult" means. Subjective assessments, such as whether a position "looks complicated" or involves many pieces, are unreliable. A position with heavy piece concentrations on the kingside may have one obviously correct move, while an apparently quiet endgame may require a deeply non-obvious maneuver. Instead, difficulty must be defined in terms of consequences: a position is difficult to the extent that a player is likely to lose value by failing to find the best continuation.
We quantify this using a concept borrowed from decision theory: expected regret. For any given position, expected regret measures the amount of win probability a player is expected to lose based on how they would actually distribute their move choices. (There is a fairly standardized mapping between "win probability" and the engine evaluation at every position.) If a player would almost certainly play the best move, the expected regret is near zero, and the position is easy. If there is a significant probability that the player would choose a move that sacrifices substantial win probability, the expected regret is high, and the position is hard. Crucially, this formulation captures both components of difficulty simultaneously: the probability of making a mistake, and the cost of making one.
A position where the best move is a quiet developing move that many alternative move choices also satisfy will produce low expected regret: even if the player doesn't find the absolute best move, the alternatives are nearly as good. A position where the best move is a non-obvious rook sacrifice and every other choice leads to a losing position will produce high expected regret: the probability of missing the sacrifice is substantial, and the cost is severe.
Difficulty Is Not One-Dimensional
A key insight that emerged during the development of this metric is that difficulty cannot be meaningfully described by a single number calibrated to one skill level. A position that presents a serious challenge to a club player may be a routine tactical pattern for a Grandmaster. A position that even a strong engine finds complex, with many candidate moves of similar evaluation that shift in ranking at higher search depths, represents a qualitatively different kind of difficulty than a position where a human struggles but an engine resolves instantly.
To address this, the difficulty metric that we have developed at Nova Chess uses multiple simulated agents at different strength levels, each producing its own expected regret for a given position. Each agent has a distinct behavioral/strength profile: given a position, it assigns probabilities to candidate moves in a manner consistent with how a player of that strength would actually choose. From these probability distributions, we derive a set of behavioral signals, such as how likely the agent is to play the engine's best move, how much of its probability mass falls on safe versus risky continuations, and how spread out its choices are across the available moves. For some agents, the move-choice model runs directly at inference time, producing exact probability distributions. For others, the behavioral signals are approximated by a compact neural network trained on hundreds of thousands of real game positions, using only information available from the board position and standard engine output (such as material balance, pawn structure, king safety, piece activity, and the engine's own candidate move evaluations). The result is a hybrid pipeline that captures the behavioral signatures of players at multiple strength levels while remaining fast enough to run in real-time.
This multi-agent approach produces a natural taxonomy of positions. Positions where only the weakest agent struggles are easy: the kind of tactic that separates a novice from a competent club player. Positions where the intermediate agents struggle but the strongest do not are hard: they require genuine calculation or pattern recognition, but a sufficiently deep search resolves them clearly. Positions where even the strongest agents register significant expected regret are very hard: these are the moments where the outcome of the game may hinge on a single decision, and the choice is genuinely difficult even for a strong player. Beyond this basic taxonomy, we further aggregate the multi-agent output into a composite difficulty score, normalized to a 0–100 scale, and displayed as a gradient (similar to an evaluation bar).
Validation
In order to test the validity of the difficulty score, we performed tests on Lichess rated puzzles as well as actual games. For the puzzles, we evaluated the difficulty score of 2,000 Lichess one-move puzzles rated between 800 and 2000 and compared the difficulty scores to puzzle ratings.
For comparing against actual games, we sourced 500 games, stratified into 5 rating buckets of 100 games each: four online player rating buckets1 centered at ratings 500, 1000, 1500, and 2000; and high-level master games (2400+ FIDE rated players). We evaluated the difficulty score at each position and compared it to the centipawn loss of the actual played move – that is, the difference in engine evaluation between the best available move and the move the player actually chose – to establish whether positions scored as more difficult by the model correspond to larger actual mistakes by human players. For the game analysis, we focused on balanced positions (where the engine evaluation indicated neither side had a decisive advantage) to isolate the effect of difficulty from the noise introduced by positions that are already won or lost.
1 Each bucket spans approximately ±100 rating points around the indicated level.
Puzzle Validation
Across 2,000 one-move Lichess puzzles stratified by rating (800–2000), the difficulty score showed strong agreement with puzzle rating. Mean and median difficulty scores were perfectly monotonic across all rating bands, and when comparing puzzle pairs separated by 500+ rating points, the model correctly identified the harder puzzle 75% of the time.
| Puzzle Rating | n | Mean Difficulty | Median Difficulty |
|---|---|---|---|
| 800–1000 | 333 | 45% | 44% |
| 1000–1200 | 333 | 53% | 54% |
| 1200–1400 | 334 | 60% | 62% |
| 1400–1600 | 333 | 67% | 69% |
| 1600–1800 | 334 | 76% | 79% |
| 1800–2000 | 333 | 86% | 90% |
Mean and median difficulty percentile by Lichess puzzle rating band. All bands are perfectly monotonic.
Game Validation: Difficulty Predicts Human Mistakes
We tested across 500 games comprising over 34,000 positions. In the positions we evaluated (filtered for positions where the engine evaluation indicated that neither side had an advantage of more than +2.00), the results show perfect monotonicity in both dimensions: positions rated as more difficult correspond to larger mistakes at every skill level, and stronger players make smaller mistakes at every difficulty level. At the 500-rated level, players lose an average of 35 centipawns on easy positions but 151 centipawns on very hard positions (4.3x ratio). Even at the master level, the ratio holds: 6 centipawns on easy positions versus 27 on very hard, a 4.5x difference. The balanced-position Spearman correlation ranged from 0.23 (masters) to 0.47 (1500-rated players) across the five cohorts.
Positions analyzed: 5,523 (500) | 7,568 (1000) | 6,450 (1500) | 7,271 (2000) | 8,124 (Master)
Breaking the results down by difficulty decile (10-percentile bands) reveals a smooth, monotonic gradient across all five cohorts:
| Decile | 500 | 1000 | 1500 | 2000 | Master |
|---|---|---|---|---|---|
| P0–P10 | 22 | 10 | 6 | 10 | 3 |
| P10–P20 | 36 | 16 | 17 | 12 | 6 |
| P20–P30 | 44 | 23 | 18 | 21 | 8 |
| P30–P40 | 60 | 30 | 29 | 28 | 10 |
| P40–P50 | 62 | 33 | 31 | 23 | 9 |
| P50–P60 | 70 | 38 | 35 | 28 | 12 |
| P60–P70 | 95 | 56 | 48 | 37 | 14 |
| P70–P80 | 102 | 58 | 61 | 46 | 16 |
| P80–P90 | 115 | 73 | 63 | 57 | 22 |
| P90–P100 | 177 | 145 | 125 | 102 | 30 |
Mean centipawn loss by difficulty decile and player rating.
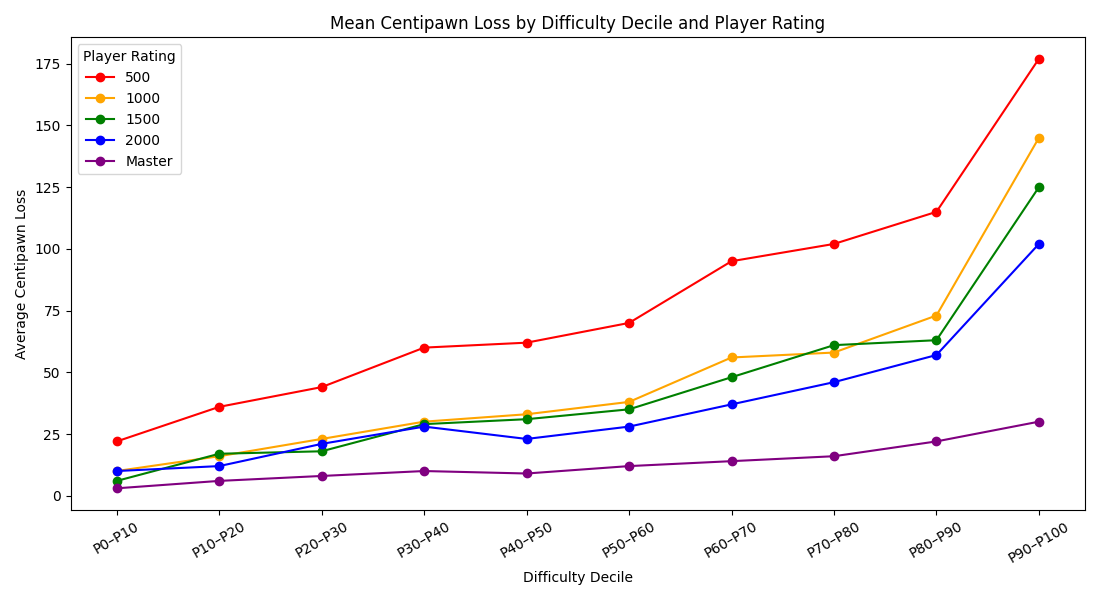
The metric captures a meaningful dimension of practical decision difficulty, as evidenced by monotonic increases in human error magnitude across difficulty deciles.
Applications
The existence of a reliable, real-time difficulty metric opens a range of applications that extend well beyond what the evaluation bar alone can provide.
Broadcast Enhancement
Perhaps the most immediately visible application is in live chess broadcasts. A difficulty indicator displayed alongside the evaluation bar would give commentators and viewers notice that a critical moment has arrived where the player-to-move is faced with a potentially difficult, game-altering decision. This transforms the viewing experience from a reactive one (watching the eval bar swing after a mistake) to an anticipatory one (knowing that the next move will test the player's ability). Positions flagged as very hard could trigger automatic highlights or alerts, helping casual viewers who may not understand the position itself to still appreciate the drama of the moment. Over the course of a broadcast, a running average of difficulty could indicate whether the game has been a tense battle or a relatively uneventful draw.
Game Analysis and Coaching
When reviewing a game, the difficulty metric reframes how mistakes should be interpreted. A blunder in a position that the metric rates as easy reveals something different about a player than a blunder in a position rated as very hard. The former may indicate a lapse in concentration or a time management failure; the latter may simply reflect the objective difficulty of the position. A coach can use this distinction to provide more targeted feedback, praising a player for finding the right move in a very hard position, or focusing remedial work on the easy positions where mistakes are less forgivable.
At a higher level of analysis, aggregating difficulty-adjusted accuracy across a collection of games produces a more meaningful picture of a player's strength than traditional accuracy metrics alone. Two players with identical accuracy scores may have faced very different levels of practical difficulty, and controlling for that difference produces a fairer and more informative comparison. A player who maintains high accuracy in very hard positions is demonstrating a measurably different skill set than one whose accuracy drops off sharply as difficulty rises.
Former World Champion Mikhail Tal famously said, "You must take your opponent into a deep, dark forest where two plus two equals five, and the path leading out is only wide enough for one." A difficulty score could also be used to assess how well a player tends to put their opponents in these types of challenging positions, and difficulty scores could serve a complementary role to traditional centipawn-loss accuracy metrics (i.e., evaluating "move choice quality" not only on raw evaluation, but also on the practical challenges it poses).
Time Management Analysis
One of the most underexplored dimensions of competitive chess performance is time management, specifically the allocation of clock time across the moves of a game. By cross-referencing the difficulty metric with the time spent per move, it becomes possible to quantify how well a player's time allocation tracks the actual difficulty of the positions they face. A player who spends excessive time on easy positions and then rushes through very hard moments has a measurable time management deficiency, regardless of the outcome of the game. Over a large sample of games, this pattern becomes a concrete, trainable skill rather than an abstract observation from a coach.
Opening Preparation
The difficulty metric also has applications in competitive preparation. Professional players spend considerable effort on opening preparation, searching for deviations from established theory that will give them an advantage. The conventional approach is to find lines where the engine evaluation favors the prepared player. But evaluation alone does not capture the practical challenge the opponent will face. A sideline that is +0.2 according to the engine but requires a series of moves rated as very hard by the difficulty metric may be far more effective in practice than one that is +0.5 but where the opponent's responses are all easy. By running the difficulty metric across the candidate moves in a deep opening line, a player can identify variations that maximize the practical challenge for their opponent, regardless of whether the engine gives a large numerical advantage.
Technical Approach
The Nova Chess difficulty score is implemented as a hybrid neural network pipeline designed to run in real-time in the browser. The pipeline combines information from two sources: standard Stockfish engine analysis (candidate moves, evaluations, and structural features of the position) and human move-choice models that predict how players of different strengths would distribute their move selections in a given position. Some of these move-choice models run directly at inference time; others are approximated by compact neural networks trained on the same behavioral targets.
Because the human move-choice models and the engine analysis produce complementary signals, combining them yields a difficulty estimate that is both behaviorally grounded and computationally efficient. The pipeline adds negligible latency to the standard engine analysis already being performed and requires no specialized hardware beyond what is used to run Stockfish.
The model is trained on hundreds of thousands of real chess game positions, with ground truth expected regret computed from the actual move distributions of different-strength agents evaluated against deep Stockfish analysis as an objective reference. The training procedure ensures that the model learns from positions representative of real games rather than from curated puzzle sets, which tend to overrepresent positions with a single correct tactical solution (as we learned from early experimentation, although we did include a small set of puzzles in the training data in order to familiarize the model with a wider range of tactical motifs). Validation across both puzzle benchmarks and real game data confirms that the model produces well-calibrated, monotonically increasing difficulty scores: positions it rates as harder correspond to measurably larger mistakes by human players across all tested skill levels, from beginner to master (see Validation Results above).
Conclusion
The evaluation bar was the first generation of engine-assisted information for chess players and viewers. It answered the question: "Who is winning?" The difficulty metric answers the next question: "How hard is the next move?" Together, they provide a substantially richer picture of what is happening in a chess game, capturing not only the objective state of the position, but the practical challenge it presents to the player who must navigate it. Our hope is that the development of this difficulty metric will lead to further advancements in chess analytics, and ultimately improve the way that players and viewers experience the game.
The difficulty metric is available in the Nova Chess analysis interface. It can be activated from the Account page under Analysis Features.